مبانی هوش مصنوعی - شبکه های عصبی
یکی دیگر از حوزههای تحقیقاتی در هوش مصنوعی، شبکههای عصبی می باشد که از شبکه عصبی طبیعی سیستم عصبی انسان الهام گرفته شده است.
شبکههای عصبی مصنوعی چیستند؟
مخترع اولین رایانهنورویی، دکتر رابرت هکت-نیلسن، یک شبکه عصبی را به شرح زیر تعریف میکند −
"...یک سامانه محاسباتی است که از تعدادی عناصر ساده و مرتبط پردازشی تشکیل شده است، که اطلاعات را در پاسخ به ورودیهای خارجی در حالت پویا پردازش میکنند.”
ساختار اساسی شبکههای عصبی مصنوعی
ایده شبکههای عصبی مصنوعی بر این باور مبنی است که عملکرد مغز انسان با ایجاد اتصالات درست، میتواند با استفاده از سیلیکون و سیمها به عنوان نورونها و دندریتها شبیهسازی شود.
مغز انسان از 86 میلیارد سلول عصبی به نام نورونها تشکیل شده است. آنها با هزاران سلول دیگر توسط آکسونها متصل هستند. محرکها از محیط خارجی یا ورودیها از اعضای حسی توسط دندریتها پذیرفته میشوند. این ورودیها نوسانات الکتریکی ایجاد میکنند که به سرعت از طریق شبکه عصبی حرکت میکنند. یک نورون میتواند پیام را به نورون دیگری ارسال کند تا مسئله را حل کند یا این پیام را به جلو نفرستد.
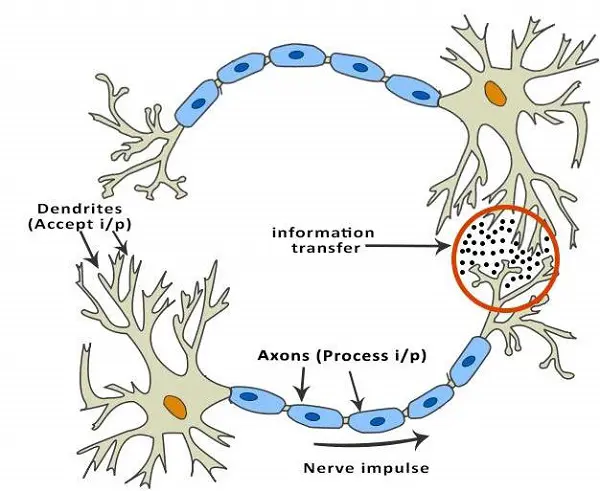
شبکههای عصبی مصنوعی از چندین گره تشکیل شدهاند که نورونهای زیستی مغز انسان را شبیهسازی میکنند. نورونها توسط پیوندها متصل هستند و با یکدیگر تعامل دارند. گرهها میتوانند دادههای ورودی را دریافت کرده و عملیات سادهای روی دادهها انجام دهند. نتیجه این عملیات به نورونهای دیگر منتقل میشود. خروجی هر گره به نام فعالیت یا مقدار گره آن نامیده میشود.
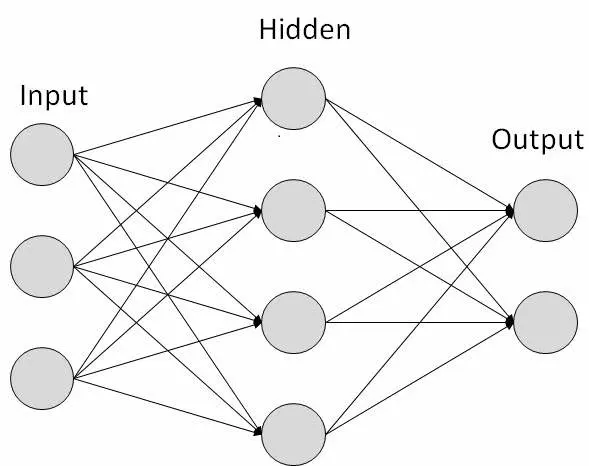
هر پیوند با وزن مرتبط است. شبکههای عصبی مصنوعی قابلیت یادگیری دارند که از طریق تغییر مقادیر وزن انجام میشود. تصویر زیر یک شبکه عصبی مصنوعی ساده را نشان میدهد −
انواع شبکههای عصبی مصنوعی
دو نوع توپولوژی شبکه عصبی مصنوعی وجود دارد − پیشرو (FeedForward ) و بازخوردی (Feedback).
شبکه عصبی پیشرو
در این شبکه عصبی، جریان اطلاعات یکطرفه است. یک واحد اطلاعات را به واحد دیگری ارسال میکند که از آن واحد هیچ اطلاعاتی دریافت نمیکند. هیچ حلقه بازخوردی وجود ندارد. این نوع شبکه در تولید الگو/تشخیص/طبقهبندی استفاده میشود. ورودیها و خروجیهای آنها ثابت هستند.
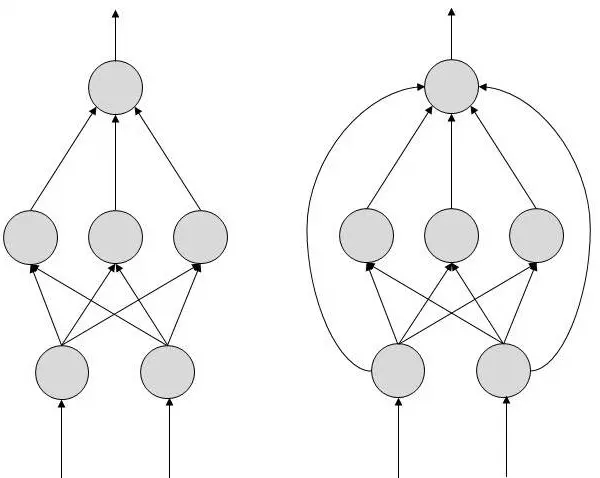
شبکه عصبی بازخوردی
در اینجا، وجود حلقههای بازخوردی مجاز هست. اینها در حافظههای قابل دسترسی به محتوا استفاده میشوند.
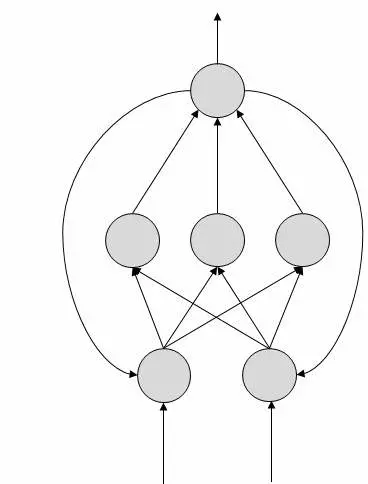
عملکرد شبکههای عصبی مصنوعی
در نمودارهای توپولوژی نشان داده شده، هر پیکان یک اتصال بین دو نورون را نشان میدهد و مسیر جریان اطلاعات را نشان میدهد. هر اتصال دارای یک وزن می باشد. وزن ، یک عدد صحیح است که سیگنال بین دو نورون را کنترل میکند.
اگر شبکه یک خروجی "خوب یا مطلوب" ایجاد کند، نیازی به تنظیم وزنها نیست. با این حال، اگر شبکه یک خروجی "ضعیف یا نامطلوب" یا خطا ایجاد کند، سیستم وزنها را تغییر میدهد تا نتایج آینده را بهبود بخشد.
یادگیری در شبکههای عصبی مصنوعی
شبکههای عصبی مصنوعی قابلیت یادگیری دارند و نیاز به آموزش دارند. چندین استراتژی یادگیری وجود دارد −
-
یادگیری نظارتشده − در اینجا یک معلم وجود دارد که داناتر از شبکه عصبی خود است. به عنوان مثال، معلم دادههایی بعنوان نمونه میدهد که در مورد آنها پاسخها را از قبل میداند.
به عنوان مثال، شناسایی الگو. شبکه عصبی در هنگام شناسایی حدس میزند. سپس معلم به شبکه عصبی پاسخ میدهد. سپس شبکه مقایسه میکند حدسهای خود را با "صحیح" پاسخهای معلم و تنظیمات لازم را بر اساس خطاها انجام میدهد.
-
یادگیری بدون نظارت − این نوع در مواردی که مجموعهدادهای با پاسخهای معلوم وجود ندارد مورد نیاز است. به عنوان مثال، جستجو برای یافتن یک الگوی پنهان. در این مورد، خوشهبندی، به اصطلاح تقسیم یک مجموعه از عناصر به گروهها بر اساس یک الگوی ناشناخته بر اساس دادههای موجود انجام میشود.
-
یادگیری تقویتی − این استراتژی بر اساس مشاهده ساخته شده است. شبکه عصبی با مشاهده محیط خود تصمیم میگیرد. اگر مشاهده منفی باشد، شبکه وزنهای خود را تنظیم میکند تا در زمان بعدی تصمیم متفاوتی بگیرد.
الگوریتم بازگشت به عقب (Back Propagation)
این الگوریتم آموزش یا یادگیری است. از طریق مثال یاد میگیرد. اگر به الگوریتم مثالی از آنچه که میخواهید شبکه انجام دهد، ارائه دهید، وزنهای شبکه را تغییر میدهد تا بتواند در پایان آموزش خروجی مطلوبی برای ورودی مشخص تولید کند.
شبکههای بازگشت به عقب برای شناسایی الگوهای ساده و وظایف نقشهبرداری ایدهآل هستند.
شبکههای بیزین (BN)
اینها ساختارهای گرافیکی هستند که برای نمایش رابطه احتمالی میان مجموعهای از متغیرهای تصادفی استفاده میشوند. شبکههای بیزین همچنین به نام شبکههای باور یا شبکههای بیز شناخته میشوند. این شبکهها در مورد دامنه ناقص اندیشه میکنند.
در این شبکهها، هر گره یک متغیر تصادفی با گزاره های خاص را نمایندگی میکند. به عنوان مثال، در حوزه تشخیص پزشکی، گره سرطان گزاره میکند که یک بیمار سرطان دارد.
یالهایی که گرهها را به هم متصل میکنند، وابستگیهای احتمالی میان این متغیرهای تصادفی را نمایش میدهند. اگر از دو گره، یکی بر دیگری تأثیر بگذارد، آنها باید به صورت مستقیم در جهت تأثیر متصل شوند. قوت رابطه بین متغیرها توسط احتمال مرتبط با هر گره اندازهگیری میشود.
تنها محدودیتی که در یک شبکه بیزین وجود دارد، این است که نمیتوانید به یک گره فقط با دنبال کردن یالهای جهتدار برگردید. بنابراین شبکههای بیزین به عنوان گرافهای جهتدار بدون دور (DAGs) نامیده میشوند.
شبکههای بیزین قادر به کنترل همزمان متغیرهای چندمقداری هستند. متغیرهای شبکه بیزین از دو بُعد تشکیل شدهاند −
- دامنه گزارهها
- احتمال اختصاص یافته به هر یک از گزارهها.
یک مجموعه متناهی X = {X1, X2, …,Xn} از متغیرهای تصادفی گسسته را در نظر بگیرید، جایی که هر متغیر Xi ممکن است ارزشها را از یک مجموعه متناهی به نام Val(Xi) بگیرد. اگر یک پیوند جهتدار از متغیر Xi به متغیر Xj, وجود داشته باشد، آنگاه متغیر Xi والد متغیر Xj خواهد بود که وابستگیهای مستقیم میان متغیرها را نشان میدهد.
ساختار BN برای ترکیب دانش اولیه و دادههای مشاهده شده ایدهآل است. شبکه بیزین میتواند برای یادگیری ارتباطات علّی و درک حوزههای مسائل مختلف و پیشبینی رویدادهای آینده، حتی در صورت وجود دادههای از دست رفته، استفاده شود.
ساخت یک شبکه بیزین
یک مهندس دانش میتواند یک شبکه بیزین ایجاد کند. در حین ایجاد آن، تعدادی مراحل وجود دارد که مهندس دانش باید آن را انجام دهد.
مثال مسئله − سرطان ریه. یک بیمار از تنگی نفس رنج می برد. او با مشکوک بودن به سرطان ریه به پزشک مراجعه می کند. پزشک می داند که به استثنای سرطان ریه، بیماری های احتمالی دیگری نیز وجود دارد که ممکن است بیمار به آن مبتلا باشد، مانند سل و برونشیت.
جمعآوری اطلاعات مرتبط مسئله
- آیا بیمار سیگاری است؟ اگر بله، پس احتمال ابتلا به سرطان و برونشیت زیاد است.
- آیا بیمار در معرض آلودگی هوا قرار دارد؟ اگر بله، چه نوع آلودگی هوا؟
- گرفتن عکس اشعه ایکس مثبت نشان دهنده سل یا سرطان ریه است.
شناسایی متغیرهای جالب
مهندس دانش سعی میکند به سوالات پاسخ دهد −
- کدام گره ها را نشان دهیم؟
- آنها چه ارزشهایی میتوانند داشته باشند؟ در چه حالتی میتوانند باشند؟
در حال حاضر بیایید تنها گرهها را در نظر بگیریم که فقط ارزشهای گسسته دارند. متغیر باید در هر زمان دقیقاً یکی از این ارزشها را داشته باشد.
انواع متداول گرههای گسسته عبارتند از −
-
گره های بولی − آنها گزارهها را نمایندگی میکنند و ارزشهای دودویی (TRUE (T) و FALSE (F)) را میپذیرند.
-
مقادیر مرتب − آلودگی گره ممکن است نشان دهنده و مقادیری از {کم، متوسط، زیاد} باشد که درجه قرار گرفتن بیمار در معرض آلودگی را توصیف می کند.
-
مقادیر صحیح − گرهی به نام Age ممکن است سن بیمار را با مقادیر احتمالی 1 تا 120 نشان دهد. حتی در این مرحله اولیه، انتخاب های مدل سازی در حال انجام است.
گرهها و ارزشهای ممکن برای مثال سرطان ریه به شرح زیر هستند −
| نام گره | نوع | ارزش | ایجاد گرهها |
|---|---|---|---|
| Pollution | دودویی | {کم، زیاد، متوسط} |  |
| Smoker | بولی | {TRUE، FALSE} | |
| Lung-Cancer | بولی | {TRUE، FALSE} | |
| X-Ray | دودویی | {مثبت، منفی} |
ایجاد یالها بین گرهها
توپولوژی شبکه باید روابط کیفی بین متغیرها را نشان دهد.
به عنوان مثال، چه چیزی باعث میشود بیمار سرطان ریه داشته باشد؟ - آلودگی و سیگار کشیدن. سپس یالها را از گره Pollution و گره Smoker به گره Lung-Cancer اضافه کنید.
به همین ترتیب اگر بیمار سرطان ریه داشته باشد، نتیجه ایکس-ری مثبت خواهد بود. سپس یالها را از گره Lung-Cancer به گره X-Ray اضافه کنید.
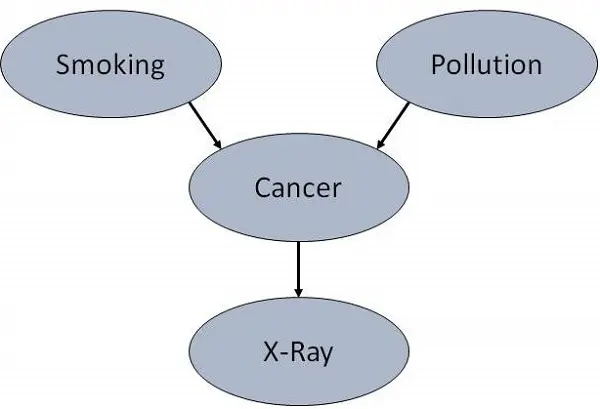
مشخص کردن توپولوژی
معمولاً، BNها به صورتی طراحی میشوند که یالها از بالا به پایین اشاره کنند. مجموعه گرههای والد یک گره X توسط Parents(X) نمایش داده میشود.
گره Lung-Cancer دو والد (دلایل یا علتها) دارد: Pollution و Smoker، در حالی که گره Smoker یک نیاکان از گره X-Ray است. به طور مشابه، X-Ray یک فرزند (نتیجه یا اثرات) گره Lung-Cancer است و جانشین گرههای Smoker و Pollution است.
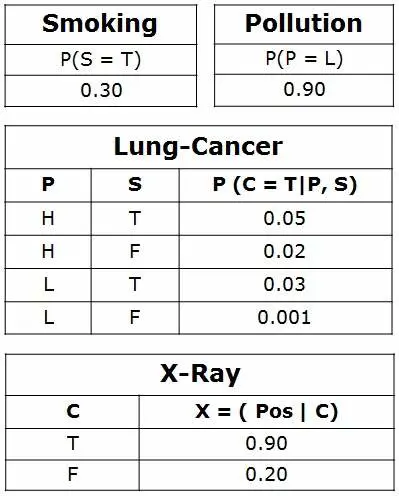
احتمالات شرطی
حالا روابط بین گرههای متصل را کمّی کنید: این کار با مشخص کردن یک توزیع احتمال شرطی برای هر گره انجام میشود. چون تنها متغیرهای گسسته در نظر گرفته شدهاند، این به صورت یک جدول احتمالات شرطی (CPT) انجام میشود.
اولاً، برای هر گره باید به تمام ترکیبهای ممکن ارزشهای این والدها نگاه کنیم. هر چنین ترکیبی، یک نمایش از مجموعه والد است. برای هر نمایش متمایز از ارزشهای والد، باید احتمالی که فرزند ممکن است بپذیرد، مشخص شود.
به عنوان مثال، والدهای گره Lung-Cancer Pollution و Smoking هستند. آنها مقادیر ممکن را دارند = { (H,T), ( H,F), (L,T), (L,F)}. جدول CPT احتمال سرطان برای هر یک از این موارد را به ترتیب <0.05، 0.02، 0.03، 0.001> مشخص میکند.
هر گره احتمالات شرطی مرتبط دارد به صورت زیر −
کاربردهای شبکههای عصبی
آنها میتوانند وظایفی را انجام دهند که برای انسان آسان است اما برای یک ماشین سخت است −
-
هوافضا − هواپیماهای خودران، تشخیص خطاهای هواپیما.
-
اتومبیل − سیستمهای راهنمایی خودرو.
-
الکترونیک − پیشبینی دنباله کد، طراحی چیپ IC، تجزیه و تحلیل خرابی چیپ، بینایی ماشین، سنتز صدا.
-
مالی − ارزیابی املاک، مشاور تسهیلات وام، انتخاب تسهیلات تورم، امتیازدهی بندرگاههای شرکتی، برنامه معاملات پورتفه، تحلیل مالی شرکتها، پیشبینی ارزش ارز، خوانندگان اسناد، ارزیابان درخواستهای اعتبار.
-
صنعتی − کنترل فرآیند تولید، طراحی و تجزیه و تحلیل محصول، سیستمهای بازرسی کیفیت، تجزیه و تحلیل کیفیت جوهر، طراحی و تجزیه و تحلیل محصولات شیمیایی، مدلسازی پویا سیستمهای فرایند شیمیایی، تجزیه و تحلیل نگهداری ماشین، مناقصهنگاری، برنامهریزی و مدیریت پروژه.
-
پزشکی − تجزیه و تحلیل سلولهای سرطان، تجزیه و تحلیل EEG و ECG، طراحی پروتز، بهینهساز زمان پیوند.
-
گفتار − شناسایی گفتار، طبقهبندی گفتار، تبدیل متن به گفتار.
-
مخابرات − فشردهسازی تصویر و داده، خدمات اطلاعات خودکار، ترجمه زبان زنده گفتار به صورت زمان واقعی.
-
حمل و نقل − تشخیص سیستم ترمز کامیون، برنامهریزی و ردیابی وسایل نقلیه.
-
نرمافزار − تشخیص الگو در شناسایی چهره، تشخیص نویسههای نوری و غیره.
-
پیشبینی سریهای زمانی − شبکههای عصبی برای پیشبینی دربارهی سهام و آتشفشانها استفاده میشوند.
-
پردازش سیگنال − شبکههای عصبی میتوانند آموزش داده شوند تا سیگنال صوتی را پردازش کنند
-
کنترل − شبکههای عصبی اغلب برای انجام تصمیمات کنترلی خودروهای فیزیکی استفاده میشوند.
-
تشخیص نقص − ازآنجاییکه شبکههای عصبی در تشخیص الگوها ماهر هستند، آموزش داده میشوند تا هنگامی که چیزی غیرعادی اتفاق بیافتد که با الگو ناسازگار است خروجی تولید کنند .