مبانی هوش مصنوعی - پردازش زبان طبیعی
پردازش زبان طبیعی (NLP) به معنای روشی بر مبنای هوش مصنوعی جهت ارتباط با سیستم های هوشمند با استفاده از یک زبان طبیعی مانند انگلیسی است.
زمانی که میخواهید یک سیستم هوشمند مانند ربات به دستورات شما عمل کند یا زمانی که میخواهید تصمیمی از یک سیستم خبره بر اساس گفتگو بشنوید، استفاده از پردازش زبان طبیعی ضروری است
زمینهٔ NLP شامل کارهایی است که کامپیوترها را قادر میسازد تا وظایف مفیدی را با زبانهای طبیعی انجام دهند که انسانها استفاده میکنند. ورودی و خروجی یک سیستم NLP میتواند به شرح زیر باشد −
- گفتار
- متن نوشتاری
اجزای NLP
دو جزء در NLP وجود دارند که به شرح زیر است −
فهم زبان طبیعی (NLU)
فهم شامل وظایف زیر است −
- نگاشت ورودی داده شده به زبان طبیعی به ارائههای مفید.
- تجزیه و تحلیل جنبههای مختلف زبان.
تولید زبان طبیعی (NLG)
این فرآیند تولید عبارات و جملات معنیدار به شکل زبان طبیعی است.
این شامل وظایف زیر است −
-
برنامهریزی متن − این شامل بازیابی محتوای مرتبط از پایگاه دانش است.
-
برنامهریزی جمله − این شامل انتخاب کلمات مورد نیاز، تشکیل عبارات معنیدار، تنظیم لحن جمله است.
-
واقعیسازی متن − این نگاشت جمله به ساختار جمله است.
NLU سختتر از NLG است.
مشکلات در NLU
زبان طبیعی یک ساختار بسیار غنی و پیچیده دارد.
این مطلب میتواند سطوح مختلفی از ابهام داشته باشد −
-
ابهام لغوی − این در سطح بسیار ابتدایی مانند سطح واژه است.
-
به عنوان مثال، چگونه کلمه "تخته" را در نظر بگیریم؟ به عنوان اسم یا فعل؟
-
ابهام ساختاری − یک جمله میتواند به روشهای مختلفی تجزیه و تحلیل شود.
-
به عنوان مثال، "او بلند کرد مورچه را با کلاه قرمز." − آیا او از کلاه برای بلند کردن مورچه استفاده کرد یا او مورچه ای را بلند کرد که کلاه قرمز داشت؟
-
ابهام ارجاعی − به چیزی با استفاده از ضمایر ارجاع میشود. به عنوان مثال، سارا پیش مریم رفت. او گفت، "من خوشحالم." −
-
دقیقاً کی خوشحال است؟
-
یک ورودی میتواند معانی مختلفی داشته باشد.
-
ممکن است چند ورودی به یک معنی برسند.
اصطلاحات NLP
-
فونولوژی − این مطالعه نحوهی سیستماتیک سازماندهی صداهاست.
-
مورفولوژی − این مطالعه ساخت واژهها از واحدهای ابتدایی معنایی است.
-
مورفم − این واحد ابتدایی معنا در یک زبان است.
-
نحو − این به ترتیب کلمات برای ساخت یک جمله اشاره دارد. همچنین درگیر تعیین نقش ساختاری کلمات در جمله و عبارات است.
-
معناشناسی − این مربوط به معنای کلمات و نحوه ترکیب کلمات به عبارات و جملات معنیدار است.
-
عملکردی − این درباره استفاده و درک جملات در شرایط مختلف است و نحوه تفسیر جمله بررسی میکند.
-
گفتمان − این به چگونگی اینکه جملهای که فوراً قبل از آن آمده است چگونه تفسیر جمله بعدی را تحت تأثیر قرار میدهد، میپردازد.
-
دانش جهان − این شامل دانش عمومی درباره جهان است.
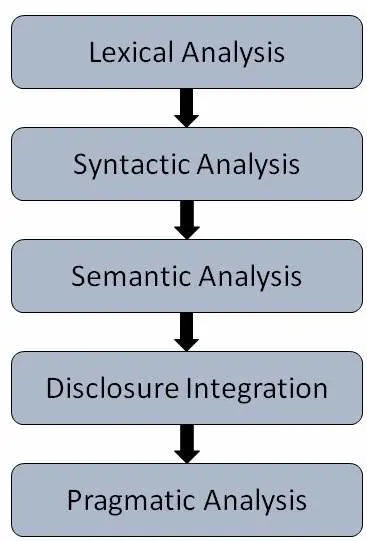
مراحل در پردازش زبان طبیعی
پنج مرحله عمومی وجود دارد −
-
تجزیه و تحلیل واژگانی − این شامل شناسایی و تجزیه و تحلیل ساختار کلمات است. واژهنامه یک زبان به مجموعهای از کلمات و عبارات در یک زبان اشاره دارد. تجزیه و تحلیل واژگانی به معنای تقسیم تکه کلان متن به پاراگرافها، جملات و کلمات است.
-
تجزیه و تحلیل نحوی (تجزیه) − این شامل تجزیه و تحلیل کلمات در جمله برای گرامر و ترتیب کلمات به نحوی است که نشاندهنده رابطه بین کلمات است. جملاتی مانند "مدرسه به پسر میرود" توسط تجزیهکننده نحوی انگلیسی رد میشود.
-
تجزیه و تحلیل معنایی − این معنای دقیق یا معنای دیکشنری را از متن استخراج میکند. متن برای معنیدار بودن بررسی میشود. این کار با نگاشت ساختارهای نحوی و اشیاء در دامنه وظیفه انجام میشود. تجزیهکننده معنایی جملاتی مانند "بستنی داغ" را نادیده میگیرد.
-
ادغام گفتمانی − معنای هر جمله به معنای جمله فوراً قبل از آن وابسته است. به علاوه، این همچنین به معنای جمله فوراً بعد از آن اشاره دارد.
-
تجزیه و تحلیل عملی − در این مرحله، آنچه گفته شده، مجدداً بر اساس آنچه واقعاً میخواسته است تفسیر میشود. این شامل استخراج آن جنبههای زبان است که نیازمند دانش واقعی جهان هستند.
جنبههای پیادهسازی تجزیهوتحلیل نحوی
تعدادی الگوریتم برای تجزیهوتحلیل نحوی توسعه دادهشده است، اما ما فقط به دو روش ساده زیر میپردازیم −
- گرامر آزاد از متن (CFG)
- تجزیهکننده بالا به پایین (Top-Down Parser)
بیایید جزئیات آنها را بررسی کنیم −
گرامر آزاد از متن (CFG)
این گرامر شامل قوانینی است که یک نماد تنها در سمت چپ قوانین بازنویسی دارد. بیایید یک گرامر بسازیم تا یک جمله را تجزیهوتحلیل کنیم −
“یک پرنده دانهها را میخورد”
حرف تعریف (DET) − یک
اسمها (Nouns) − پرنده | پرندگان | دانه | دانهها
عبارت اسمی (NP) − حرف تعریف + اسم | حرف تعریف + صفت + اسم
= DET N | DET ADJ N
فعلها (Verbs) − میخورد | میخورند | میخوردند
عبارت فعلی (VP) − NP V | V NP
صفات (ADJ) − زیبا | کوچک
درخت تجزیهوتحلیل جمله را به اجزای ساختاری شکسته و تقسیم میکند تا کامپیوتر بتواند آن را به راحتی درک و پردازش کند. برای الگوریتم تجزیهوتحلیل این درخت تشکیل دهد، یک مجموعه از قوانین بازنویسی باید ساخته شود، که توصیف میکنند چه ساختارهای درختی مجاز هستند.
این قوانین میگویند که یک نماد خاص ممکن است با دنبالهای از نمادهای دیگر در درخت گسترده شود. طبق قاعدهٔ منطقی اول، اگر دو رشته «عبارت اسمی (NP)» و «عبارت فعلی (VP)» وجود داشته باشد، رشته ایجاد شده توسط NP دنباله VP یک جمله است. قوانین بازنویسی برای جمله به شرح زیر هستند −
S → NP VP
NP → DET N | DET ADJ N
VP → V NP
(Lexicon) −
DET → a | the
ADJ → زیبا | کوچک
N → پرنده | پرندگان | دانه | دانهها
V → میخورد | میخورند | میخوردند
درخت تجزیهوتحلیل میتواند به شکل زیر ایجاد شود −
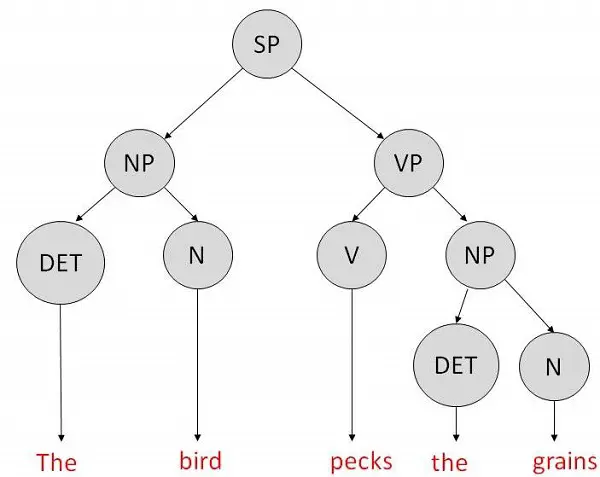
حالا قوانین بازنویسی فوق را در نظر بگیرید. از آنجایی که V میتواند توسط "میخورد" یا "میخورند" جایگزین شود، جملاتی مانند "پرنده دانهها را میخورند" به اشتباه ممکن است مجاز شوند. به عبارت دیگر، خطا در تطابق فاعل و فعل به عنوان درست تأیید میشود.
مزیت − سادهترین نوع گرامر، بنابراین گستردهترین استفاده را دارد.
نقاط ضعف −
-
آنها بسیار دقیق نیستند. به عنوان مثال، "دانهها پرنده را میخورند"، از نظر نحوی درست است، اما حتی اگر معنایی نداشته باشد، پارسر آن را به عنوان یک جمله درست میپذیرد.
-
برای دقت بالا، نیاز به چندین مجموعه گرامر و قوانین مختلف برای تجزیه و تحلیل نیاز است. این ممکن است نیاز به مجموعههای کاملاً متفاوت از قوانین برای تجزیه و تحلیل تغییرات تک و جمع، جملات فعال و ... داشته باشد که ممکن است منجر به ایجاد مجموعههای بزرگ و نامداری شود که قابل مدیریت نیستند.
تجزیهکننده بالا به پایین (Top-Down Parser)
در اینجا، پارسر با نماد S شروع به کار میکند و سعی میکند آن را به یک دنباله از نمادهای پایانی بازنویسی کند که با کلاسهای کلمات در جمله ورودی همخوانی دارد تا کاملاً از نمادهای پایانی تشکیل شود.
سپس اینها با جمله ورودی بررسی میشوند تا ببینیم آیا همخوانی دارند یا خیر. اگر ندارند، فرآیند با مجموعه دیگری از قوانین دوباره آغاز میشود. این کار تا زمانی ادامه دارد که یک قاعده خاص پیدا شود که ساختار جمله را توصیف میکند.
مزیت − پیادهسازی آن ساده است.
نقاط ضعف −
- کارایی آن کم است، چرا که در صورت بروز خطا فرآیند جستجو باید مجدداً تکرار شود.
- سرعت کار کم است.