آموزش سیستم مدیریت پایگاه داده - شاخصگذاری
ما میدانیم که دادهها به صورت رکوردها ذخیره میشوند. هر رکورد یک فیلد کلیدی دارد که به شناسایی یکتا آن کمک میکند.
شاخصگذاری (ایندکسینگ) یک تکنیک ساختار داده است که به صورت کارآمد امکان بازیابی رکوردها از پروندههای پایگاه داده را بر اساس برخی ویژگیها که شاخصگذاری بر روی آنها صورت گرفته است، فراهم میکند. ایندکسگذاری در سیستمهای پایگاه داده شباهتی به آنچه در کتابها مشاهده میکنیم دارد.
شاخصگذاری بر اساس ویژگیهای تعریف میشود. میتواند از انواع زیر باشد:
-
ایندکس اصلی - ایندکس اصلی بر روی پروندهی دادههای مرتب شده تعریف میشود. پروندهی داده بر اساس یک فیلد کلیدی مرتب میشود. فیلد کلیدی معمولاً کلید اصلی رابطه است.
-
ایندکس ثانویه - ایندکس ثانویه ممکن است از یک فیلدی تولید شود که یک کلید نامزد با مقدار یکتا در هر رکورد دارد یا یک فیلد غیرکلیدی با مقادیر تکراری.
-
ایندکس خوشهبندی - ایندکس خوشهبندی بر روی پروندهی دادهای مرتب تعریف میشود. پروندهی داده بر اساس یک فیلد غیرکلیدی مرتب میشود.
ایندکسگذاری مرتب دو نوع دارد:
- ایندکس متراکم
- ایندکس پراکنده
ایندکس متراکم
در ایندکس متراکم، برای هر مقدار کلید جستجو در پایگاه داده یک رکورد ایندکس وجود دارد. این امر باعث افزایش سرعت جستجو میشود اما نیازمند بیشترین فضا برای ذخیره رکوردهای ایندکس است. رکوردهای ایندکس شامل مقدار کلید جستجو و اشارهگری به رکورد واقعی در دیسک هستند.

ایندکس پراکنده
در ایندکس پراکنده، برای هر مقدار کلید جستجو، رکوردهای ایندکس ایجاد نمیشوند. یک رکورد ایندکس در این حالت شامل یک کلید جستجو و یک اشارهگر واقعی به داده در دیسک است. برای جستجوی یک رکورد، ابتدا با استفاده از رکورد ایندکس به مکان واقعی داده میرسیم. اگر دادهای که به دنبال آن هستیم در مکانی که به طور مستقیم با پیروی از ایندکس به آن میرسیم وجود نداشته باشد، سیستم به جستجوی ترتیبی میپردازد تا داده مورد نظر پیدا شود.

ایندکس چندسطحی
رکوردهای ایندکس شامل مقادیر کلید جستجو و اشارهگرهای داده هستند. ایندکس چندسطحی در کنار پروندههای واقعی پایگاه داده در دیسک ذخیره میشود. همانطور که اندازه پایگاه داده افزایش مییابد، اندازه ایندکسها نیز افزایش مییابد. نیاز بسیاری به نگهداری رکوردهای ایندکس در حافظه اصلی وجود دارد تا عملیات جستجو را سریعتر کند. اگر از ایندکس یک سطحی استفاده شود، به این معناست که نمیتوان اندازهی بزرگی از ایندکس را در حافظه نگهداری کرد که باعث میشود نیاز به دسترسی چندباره به دیسک پیش بیاید.
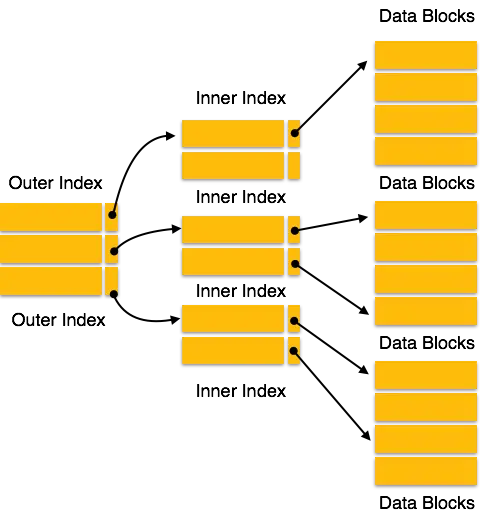
اندکس چندسطحی به شکستن ایندکس به چندین ایندکس کوچکتر کمک میکند تا سطح بیرونی به گونهای کوچک باشد که بتوان آن را در یک بلاک دیسک ذخیره کرد که به راحتی در هر جای حافظه اصلی جا میگیرد.
درخت B+
یک درخت B+ یک درخت جستجوی دودویی تعادلشده است که فرمت ایندکس چندسطحی را دنبال میکند. گرههای برگ درخت B+ نشاندهندهی اشارهگرهای داده واقعی هستند. درخت B+ تضمین میکند که تمام گرههای برگ به ارتفاع یکسان باقی میمانند و بنابراین تعادلشده هستند. علاوه بر این، گرههای برگ با استفاده از لیست پیوندی متصل شدهاند؛ بنابراین درخت B+ میتواند هم از دسترسی تصادفی و هم از دسترسی متوالی پشتیبانی کند.
ساختار درخت B+
هر گره برگ از فاصلهی مساوی با گره ریشه قرار دارد. درخت B+ از مرتبه n است که n برای هر درخت B+ ثابت است.

گرههای داخلی −
- گرههای داخلی (غیر برگ) شامل حداقل ⌈n/2⌉ اشارهگر هستند، به جز گره ریشه.
- حداکثر یک گره داخلی میتواند شامل n اشارهگر باشد.
گرههای برگ −
- گرههای برگ شامل حداقل ⌈n/2⌉ اشارهگر رکورد و ⌈n/2⌉ مقدار کلید هستند.
- حداکثر یک گره برگ میتواند شامل n اشارهگر رکورد و n مقدار کلید باشد.
- هر گره برگ شامل یک اشارهگر بلوک P برای اشاره به گره برگ بعدی است و یک لیست پیوندی شکل میدهد.
درج درخت B+
-
درختهای B+ از پایین پر میشوند و هر مورد در گره برگ انجام میشود.
- اگر یک گره برگ سربالا شده باشد −
-
گره را به دو بخش تقسیم کنید.
-
تقسیم در جایگاه i = ⌊(m+1)/2⌋ انجام شود.
-
اولین i مورد در یک گره ذخیره میشود.
-
بقیه موارد (شروع از i+1) به یک گره جدید منتقل میشوند.
-
کلید iام در والدین گره برگ تکرار میشود.
-
-
اگر یک گره غیر برگ سربالا شده باشد −
-
گره را به دو بخش تقسیم کنید.
-
تقسیم گره در جایگاه i = ⌈(m+1)/2⌉ انجام شود.
-
موارد تا i را در یک گره نگه دارید.
-
بقیه موارد به یک گره جدید منتقل میشوند.
-
حذف درخت B+
-
موارد درخت B+ در گرههای برگ حذف میشوند.
-
مورد هدف را جستجو کرده و حذف کنید.
-
اگر یک گره داخلی باشد، آن را حذف کرده و با مورد از موقعیت سمت چپ جایگزین کنید.
-
-
بعد از حذف، تحتجریانی بررسی میشود،
-
اگر تحتجریانی رخ دهد، موارد را از گرههای سمت چپ توزیع کنید.
-
-
اگر توزیع از سمت چپ امکانپذیر نباشد، آنگاه
-
از گرههای سمت راست به سمت آن توزیع کنید.
-
-
اگر توزیع از سمت چپ و یا سمت راست امکانپذیر نباشد، آنگاه
-
گره را با گره سمت چپ و راست آن ادغام کنید.
-